Python for Marketers: Searching Facebook ad library
- What this is for: Querying Facebook’s ad library for political or issue ads and downloading results to .CSV
- Requirements: Verified Facebook ID, Facebook developer account, Basic understanding of APIs and Pandas dataframes
In 2019, Facebook launched its Ad Library to improve transparency in advertising, allowing anyone to easily search ads that pages are running.
While the tool is easy to use, there may be cases where you need something a little more advanced – perhaps if you want to automate reporting or collect large volumes of data.
Enter the API. With the Facebook Graph API, you can automate reporting of Facebook ads. Unfortunately, the API will not allow you to search all Facebook ads at this time. You can only search political or issue ads, but hopefully this will be expanded in the future to include other types of ads.
Getting Started
There are couple steps you will need to take before you can dive in. These steps are detailed on the Facebook Ads Library API page, but here is a high level overview:
- Confirm your identity. You’ll need to verify your identity because the API deals with ads for political issues. Facebook will require you to upload a photo ID and then mail you a code to your physical address. It took me about 4-5 days to get my code in the mail.
- Create a Facebook developer account.
- Create a new App in your Facebook developer account.
You will also need to install the Facebook SDK into your Python environment if you haven’t already. To to this, open command prompt in Windows (or terminal on Mac) and type in:
pip install facebook-sdk
Graph Explorer
I would also encourage you to become familiar with Facebook’s Graph API Explorer so that you can practice making API calls.
The Facebook documentation uses the example of searching ads that contain the word “California.”
To try this out, navigate to the Graph API Explorer. You may need to generate an access token if you haven’t already.
Select GET method and the latest API version from the dropdowns.
Paste the following as your API endpoint (don’t forget to paste your access token, found on the right side of the Graph Explorer):
ads_archive?access_token=paste_your_access_token_here&fields=page_id,page_name,ad_snapshot_url&search_terms='california'&ad_type=POLITICAL_AND_ISSUE_ADS&ad_reached_countries=['US']&limit=25
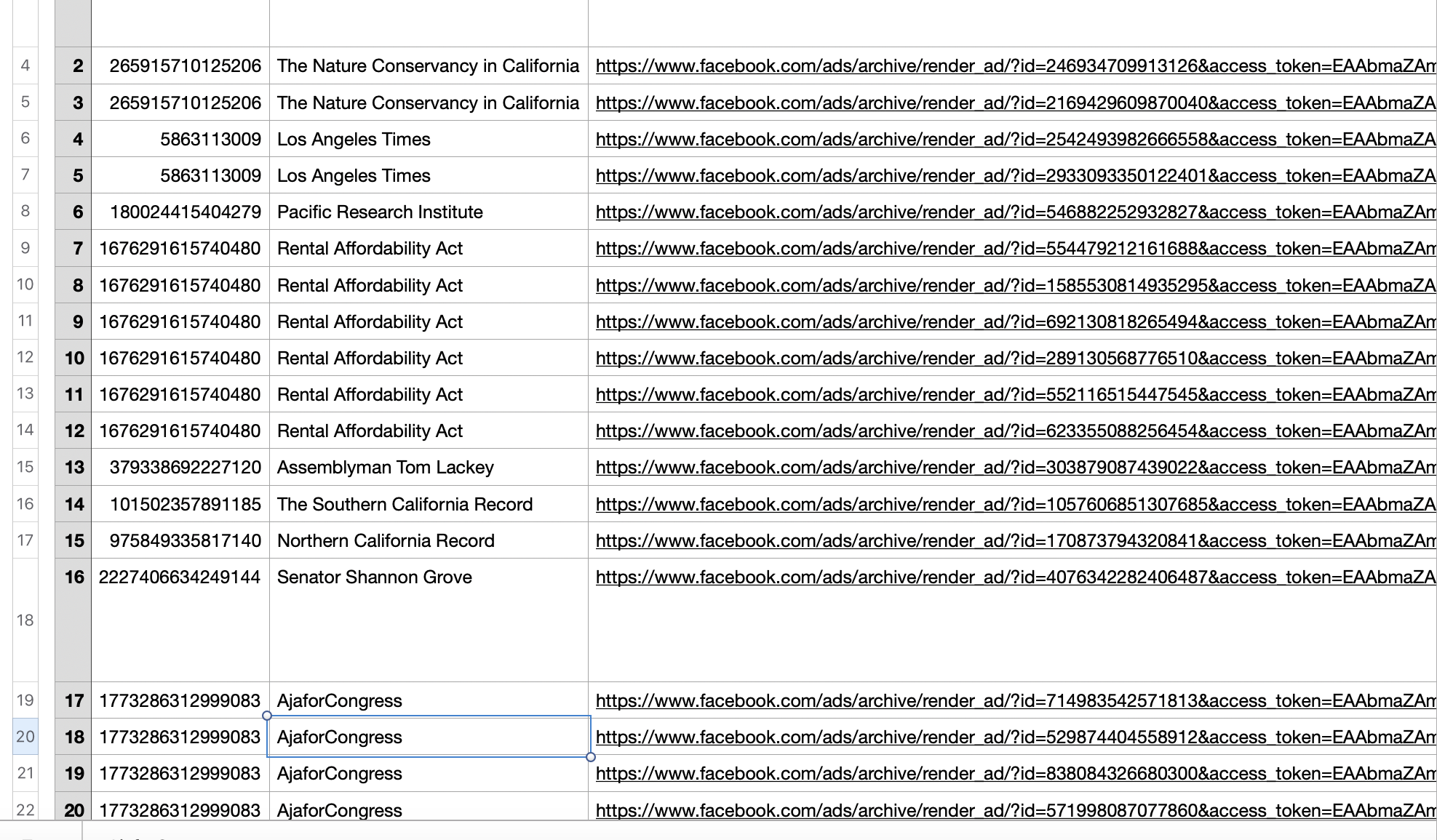
This will return a list of ads structured in JSON format with data on page ID, Page Name, and a URL for the ad. If you want to add additional fields, simply add them to “fields=” section of the URL separated by a comma. A complete list of available fields and other search querying capabilities are listed in the API documentation.
For instance, you can also add filters or search by specific page IDs. You could also modify the fields to collect information such as spend and demographic targeting.
Python Code
To make this same request using Python, the code is pretty straightforward. First, we’ll import our libraries.
import facebook import requests import urllib3 import json import pandas as pd import csv
Next, we’ll make the request and save the results to a JSON file. Again, don’t forget to paste your token inside the quotes on the second line.
def main():
token = "paste your token here"
graph = facebook.GraphAPI(token)
#define parameters for request
profile = graph.get_object('ads_archive',fields='page_id,page_name,ad_snapshot_url',search_terms='california',ad_type='POLITICAL_AND_ISSUE_ADS',ad_reached_countries=['US'])
#return desired fields
print(json.dumps(profile, indent=4))
#save results as json file
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(profile, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
main()
At this point, our data is saved in JSON format. However, this won’t be very useful if you want to share the data with others or manipulate the data outside of Python.
We’ll need to convert the JSON file to a CSV, which is really simple using Pandas. Because the data we want is nested as an object under “data: […” we’ll need to specify this in the second line:
results = json.load(open('data.json'))
df = pd.DataFrame(results["data"])
df.to_csv('data.csv')
And here’s the result!